今天會將昨天訓練好的翻譯模型在測試資料集進行預測,若進度符合期待,將會使用 BLEU 分數來評估模型的翻譯能力,關於此評測機制的詳細原理與範例程式碼可見下方參考文章[1][2]。
我們可將昨天訓練好的 Keras 模型與其權重從硬碟載入程式中,不需要再經過漫長的學習歷程(與教育部公告的108課綱無關):
from tensorflow.keras.models import load_model
# load pre-trained model
eng_cn_translator = load_model("models/eng-cn_translator_v1.h5")
我們讓模型預測每一筆測試資料,並打印出第一個英文句子的輸出結果:
# predict model
trans_seqs = eng_cn_translator.predict(
X_test,
batch_size = 60,
verbose = 1,
use_multiprocessing = True
)
print(trans_seqs[0])
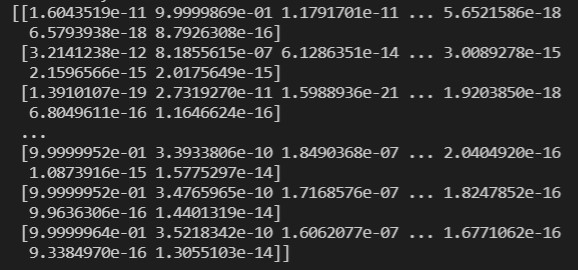
以上顯示為 X_test 當中第一個句子的神經網絡原始輸出,其為每個時間點屬於每個經過 one-hot 編碼單詞的機率。我們可以透過以下函式來預測一個句子:
def pred_seq(model, single_seq_pair, reverse_tgt_vocab_dict):
"""
Predicts a single sentence
---------------------------
single_seq_pair:
sequence pair that is made up of only one source sequence and one target sequence [(src_max_seq_length, ), (tgt_max_seq_length, )]
type: list of NumPy arrays
"""
# print("raw prediction: ", model.predict(single_seq_pair))
# model gives a one-hot encoded array
pred = model.predict(single_seq_pair)[0]
# turns into label encoded array (word_id's)
pred_le = [np.argmax(oneHot_vec) for oneHot_vec in pred]
# print("pred_le: ", pred_le)
pred_tokens = []
for id in pred_le:
try:
word = reverse_tgt_vocab_dict[id]
pred_tokens.append(word)
except KeyError:
break
return ' '.join(pred_tokens)
# predict the 5th sentence in X_test
i = 5
# ground truth sentences
print("actual source sentence: {}".format([reverse_src_vocab_dict[id] for id in X_test[0][i] if id != 0]))
print("actual target sentence: {}".format([reverse_tgt_vocab_dict[id] for id in X_test[1][i] if id != 0]))
首先我們來看真實的英文輸入句以及中文對應句:
以及翻譯模型預測的結果:
可以看得出「忠」被翻譯成了「丈」,其餘單詞皆精準預測,至於這樣的翻譯效果好與不好呢?請見下回介紹如何以 BLEU 分數來評估翻譯器的好壞。
我們目前利用了模型翻譯單一個句子,然而尚未走完模型訓練的階段。以下為翻譯實作任務的幾項殘留課題:
今天發出了第三十篇文章,也完成了鐵人賽。然而此系列文將會介紹完整個翻譯器的實作任務,因此明天還會再相見,各位晚安~~

